What are single-table designs?
In a database management system, a single table is designed to obtain data of heterogeneous items. A single-table design with DynamoDB resolves the issue of raising multiple requests for the relevant data of an entity.
Single-table design patterns, in which one database table supports the whole application and holds various application entities, have grown into DynamoDB best practices. By minimizing the number of requests required to retrieve information, this design pattern improves performance. It also reduces operational costs. Decoupling the entity key fields and attributes from the physical table structure substantially facilitates the change and evolution of DynamoDB designs.
The recent rise in single-table designs is due to the tireless work of educators like Alex Debrie and Rick Houlihan. They helped to better understand how to model DynamoDB data in a single-table design and the availability of modeling tools like Amazon NoSQL Workbench for DynamoDB Data with streamlined access libraries such as OneTable.
Why OneTable?
The process of using OneTable for single-table designs differs from the traditional approach. The key difference is that OneTable uses a schema to define the application entities, keys, attributes, and table indexes. Having the application indexes, entities, and keys defined in one place is better than being scattered throughout the application.
The single-table design process
The single-table design is an iterative process and consists of the following steps:
- Determine the application entities and relationships.
- Determine all the access patterns.
- Determine the key structure and entity key values.
- Codify the design as a OneTable schema.
- Create a OneTable migration script to populate test data.
- Prototype queries to satisfy each of the access patterns.
- Repeat and refine.
Before going in-depth on how we can perform operations in a single request using a single-table design without needing a costly join operation, let us discuss SQL modeling and joins.
SQL modeling and joins
The concept of Joins is used in Structured Query Language (SQL) for relational database query. Joins facilitate the reading of the data of two or more tables at a time by combining the columns of the tables relationally.
For example, in an e-commerce application, you will have to create one table for customers and one table for orders. Both tables will have three columns each, as shown below:
| Customers | ||
| CustomerId | CustomerName | CustomerBirthdate |
| 741 | John Dalton | 05/25/2021 |
| 742 | Charles Darwin | 03/14/2021 |
| Orders | ||
| OrderId | CustomerId | OrderDate |
| 11578 | 741 | 12/20/2021 |
| 11579 | 910 | 12/20/2021 |
The problem of missing joins in DynamoDB
DynamoDB does not use the concept of joins. Fetching the data requires multiple serial requests to obtain the relevant data of an entity. Although the developers apply relational design patterns with DynamoDB, it is not an efficient way to manage large-scale data.

The solution: pre-join your data into item collections
Applying pre-join to your data items will fetch rapid results and consistent performance from DyanmoDB.
Consider the example of an e-commerce application. The application has the user data and order records of the user. The order records for a particular user are always live. While accessing the relevant data, if a pre-join has been done, the order records for that user can be fetched in a single request.
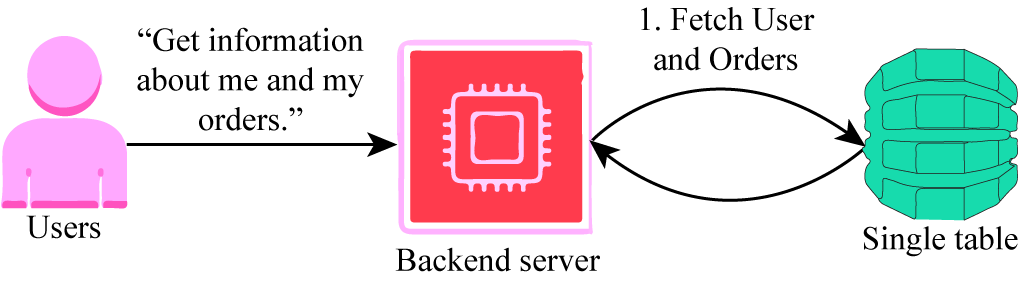
This is the benefit of single table design in which fewer requests can fetch multiple details
Before creating a OneTable schema, you should understand an Entity Relationship Diagram (ERD).
What is an Entity Relationship diagram?
An entity relationship diagram is a flowchart representing the data relevant to a particular user or object. ERDs are often used for modeling relational databases. This flowchart uses the same symbol used in a business model. Shapes like rectangles, diamonds, circles, ovals, and arrows are its main components.
How to create an ERD?
Following are the steps to construct an ERD:
- Identify the entities: It is the first step of drawing an ERD. You need to identify the entities as per your product. These entities can be the customer name, user identity, zonal/regional tag, invoice, manager, etc. Entities are usually kept in a rectangular box. You can use multiple and multilayer entities as per the product's need.
- Identify relationships: Identifying the relationship between two entities is the most important step. This will help you segregate the stages and eventually form the flowchart. A solid line usually shows the relationship in an ERD.
- Describe the relationship: A diamond shape is used to describe the relationship between the entities. It is put on the line showing the relationship between the entities.
- Add attributes: They represent properties associated with the entities.
- Complete the diagram: The final step is to complete the diagram after identifying all the possible relationships and stages that define multiple relationships.
Examples of simple entity relationship diagrams
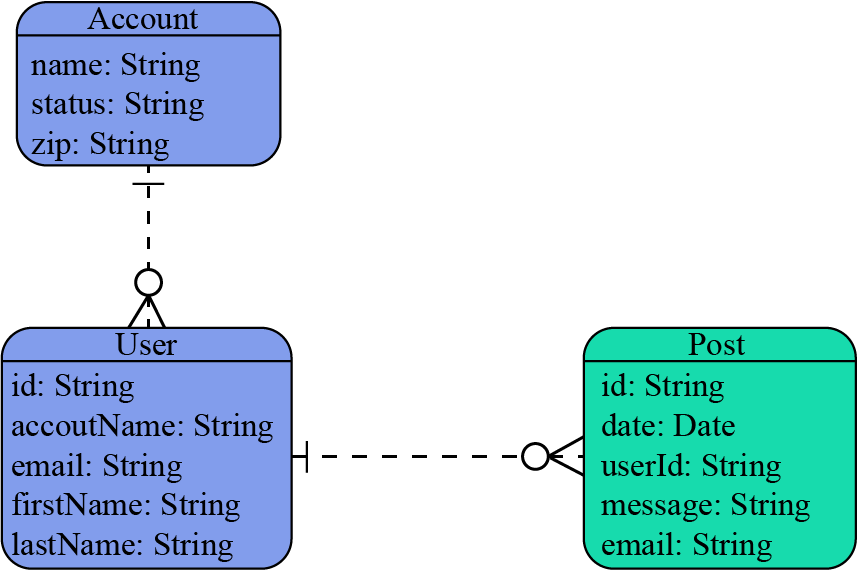
- An ERD for a trivial blog application with entities for Accounts, Users, and Blog Posts.
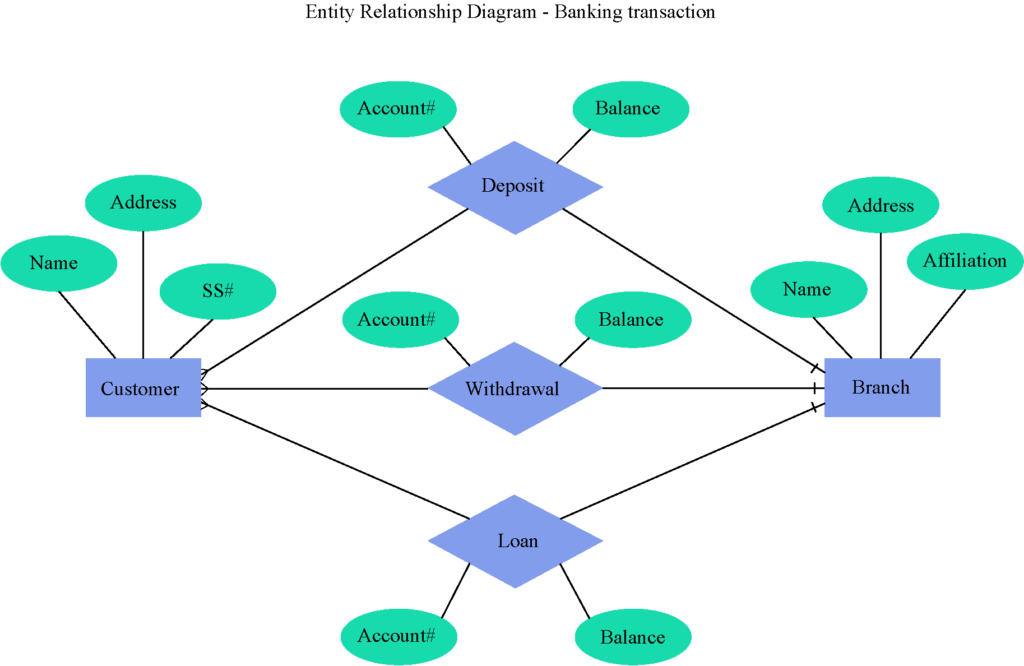
- An ERD for Banking transactions with entities for Customer, Withdrawal, Loan, Deposit, and Branch.
Creating a OneTable schema
You can code your design as a OneTable schema by creating a “model” for each entity. List each entity attribute and identify the primary key for it. Let us create a OneTable Schema for a trivial blog application with entities for Accounts, Users, and Blog Posts.
The primary and secondary keys of the physical database should have generic names like pk and sk for partition and sort keys. For secondary indexes, they should have equally generic names like gs1pk and gs1sk.
const MySchema = { indexes: { primary: { hash: 'pk', sort: 'sk', }, gs1: { hash: 'gs1pk', sort: 'gs1sk', } }, models: { Account: { pk: { value: 'account#${name}' }, sk: { value: 'account#' }, name: { type: String }, address: { type: String }, }, User: { pk: { value: 'account#${accountName}' }, sk: { value: 'user#${email}' }, gs1pk: { value: 'user#${email}' }, gs1sk: { value: 'account#${accountName}' }, accountName: { type: String }, email: { type: String }, }, Post: { pk: { value: 'post#${email}' }, sk: { value: 'post#${id}' }, gs1pk: { value: 'user#${email}' }, gs1sk: { value: 'post#${id}' }, id: { type: String, lsid: true }, date: { type: Date }, message: { type: String }, email: { type: String }, } },}Downsides of a single-table design
- The steep learning curve to understand single-table designs
A single table looks weird and quite different from the normal clean table. While getting all the relevant data with one request is easy, it is hard to analyze it for multiple entities.
- Inflexibility in adding new access patterns
Single tables are defined in the prescribed format. New access patterns cannot be easily accumulated with the existing ones. Hence, inflexibility is a major demerit of single tables.
- Difficulty in exporting tables for analytics
Analyzing a single table is quite difficult due to its complexity and interconnectivity. So, to analyze the data of the table, you need to restructure it to the previous normal form.
Common Mistakes
You should not use a single-table design in DynamoDB on the following two occasions:
- Using a single-table design in new applications is not recommended as they may require frequent changes.
- It is not recommended to use single-table designs with applications of GraphQL as it may be confused with ERD and the features of GraphQL.
Context and Applications
This topic is significant in the professional exams for graduate and postgraduate courses,
especially:
- Bachelor of Arts Program with Computer Applications
- Bachelor of Engineering in Computer Science and Engineering
- Bachelor of Science in Computer Science
- Master of Science in Computer Science
- Master of Technology in Computer Science and Engineering
Related Concepts
- Amazon DynamoDB Data Modeler
- DynoBase GUI Client
- OneTable Migrate Library
Practice Problems
Q.1 SQL is an abbreviation for:
(A) Syntax Query Language
(B) Sample Query Language
(C) Structured Query Language
(D) Sequence Query Language
Correct Option: (C)
Explanation: SQL is the abbreviation for Structured Query Language.
Q.2 Which of the following is not a process to take single table backup in SQL server?
(A) Bulk Copy Program (BCP)
(B) Export Data using SSIS to any destination
(C) Make a copy of the table using SELECT INTO
(D) Sequence Query Language
Correct Option: (D)
Explanation: SELECT INTO is a simple query in SQL. This cannot be interpreted as a backup process.
Q.3 Which of the following is not a data type in SQL?
(A) CHAR
(B) FLOAT
(C) NUMERIC
(D) STRING
Correct Option: (D)
Explanation: There is no STRING data type in SQL. The string are stored as CHAR(length) or VARCHAR(length).
Q.4 Which of the following is also called an INNER JOIN?
(A) NON-EQUI JOIN
(B) EQUI JOIN
(C) PARALLEL JOIN
(D) SELF JOIN
Correct Option: (B)
Explanation: EQUI JOIN is also called INNER JOIN, as it joins the rows from both tables, where the condition is satisfied.
Q.5 To modify a table definition in SQL use:
(A) Modify
(B) Select
(C) Alter
(D) Update
Correct Option: (C)
Explanation: There is no Modify keyword in SQL. The Alter keyword is used to modify (alter) the table.
Want more help with your computer science homework?
*Response times may vary by subject and question complexity. Median response time is 34 minutes for paid subscribers and may be longer for promotional offers.
Search. Solve. Succeed!
Study smarter access to millions of step-by step textbook solutions, our Q&A library, and AI powered Math Solver. Plus, you get 30 questions to ask an expert each month.
Search. Solve. Succeed!
Study smarter access to millions of step-by step textbook solutions, our Q&A library, and AI powered Math Solver. Plus, you get 30 questions to ask an expert each month.